Website crawling is the automated process of systematically browsing and downloading content from website pages, typically for indexing and analyzing the website's content. In this article, you will learn how website crawling works and why it’s important for your website’s SEO.
What is a Web Crawler or Bot?
A web crawler, also known as a spider, or search engine bot is a software program that will visit a website and follow links to pages on the site, downloading the content of each page it visits.
As the crawler discovers pages, it will then extract information from the pages it downloads, such as text, images, and other media, and use this information to build an index of the website's content.
Examples of Search Engine Web Crawler Bots
A few examples of search engine bots that are widely used are:
Googlebot - Google's search engine crawler
Amazonbot - Amazon’s web crawler
Bingbot - Microsoft Bing’s search engine crawler
Yahoo Slurp - Yahoo's search engine crawler
DuckDuckBot - the crawler for the search engine DuckDuckGo
Yandex Bot - the crawler for the Yandex search engine in Russia
Baidu - the Chinese search engine Baidu’s crawler
How Do Web Crawlers Work?
Web crawlers start with what they already have, for example, a single link, a list of known URLs, or a domain. This is the starting point where the crawler enters the website to begin the crawling process.
As the web crawler lands on a web page, it discovers links on the page, which it then queues for crawling next. Think of it as a tree where you start on the trunk, discover the main branches and each branch will have smaller branches, and so forth until the leaves are reached.
It’s important to understand that web crawlers don’t crawl every link - in fact, bots will follow certain policies that make them selective about which pages to crawl, in what order, and how often they should come back to check for content updates. This conserves the crawler’s server resources and makes the process more efficient.
Search engines will use the relevant importance of a website to determine how to prioritize crawling. Factors that influence this include the number of backlinks, internal links, outbound links, the traffic of the website, domain & page authority, etc.
The web crawler generally references three primary things when deciding on whether or not to crawl a page:
Robots.txt File
This is a file that lives on the website’s server that specifies the rules for any bots that access the website. These rules can define which pages the bots can or cannot crawl, which links they can or cannot follow, and how quickly they can crawl the website. Every search engine bot or web crawler behaves differently, and some proprietary third-party web crawlers may not follow these rules.
Below is an example of the robots.txt file for hikeseo.co. Below is an example of the robots.txt file for hikeseo.co. The asterisk (*) wildcard assigns directives to every user-agent, which applies the rule for all bots. That means in this example, the /wp-admin/ page will not be crawled at all, whereas the /wp-admin/admin-ajax.php page is to be crawled by all bots.
Robots Meta Tag
The robot's meta tag is situated in the head section of an HTML web page and can have various attributes that define how a page should be crawled or indexed. To inform crawlers not to follow any of the links on a page, this is the robots meta tag that should be used:
<meta name="robots" content="nofollow">
Link Attributes
Every hyperlink can contain an attribute to specify whether they want web crawlers to dofollow or nofollow it. In other words, this attribute tells the bot whether they should (dofollow) or should not (nofollow) crawl that page.
By default, all links are dofollow links unless they are manually modified to be nofollow links as in the above example, or are defined otherwise in the Robots.txt file.
What Types of Crawls Exist?
There are two types of crawls:
Site Crawls - This involves crawling the entire website until all links have been exhausted and no new pages have been found. This process is also called “Spidering”. Page Crawls - This is simply crawling a single page URL.
Two Types of Google Crawls
Google has two types of crawls that it does on websites:
Discovery - where the GoogleBot discovers new web pages to add to its index Refresh - where the GoogleBot finds changes in webpages that it has already indexed previously
Why are Web Crawlers Called Spiders?
You may have heard the term “spiders” or “spidering” used to describe web crawling. Even the term “crawling” almost implies it’s a creature.
Because the web or World Wide Web (www) is called as it is, it was only natural to name search engine bots “spiders” because they essentially crawl over the web and continue to expand the known web with discovered pages and websites, just as real spiders crawl over and spin new webs.
How To Control Web Crawler Bots On Your Website
Because some websites are hosted on servers with limited resources and bandwidth, some webmasters choose to limit the activity of web crawlers on their websites. Also, webmasters may not want web crawlers to visit every web page on their site, because some may be intended as pages for marketing campaigns or private pages that only users with the direct link can access.
There are two ways to inform bots not to crawl a publicly accessible page or set of pages:
NoIndex Attribute
The noindex attribute is located in the robots meta tag that can be added to a page to indicate to search engine crawlers that this page should not be indexed within the search results. Here’s how it should be configured to prevent search engines from indexing it:
<meta name="robots" content="noindex">
Disallow Directive
The disallow directive is a rule in the robots.txt file that informs search engines to not crawl a specific page or a whole directory of pages on a website.
For example, to prevent bots from crawling the /learn/ directory of pages, the following directive would be added to the file:
User-agent: * Disallow: /learn/
The wildcard symbol * is synonymous with “any” or “all”, so in this context, it would apply to all user agents (web crawlers).
Web Crawling vs. Web Scraping?
You might be wondering what the difference is between web crawling and web scraping.
Essentially, web scraping is when a bot downloads the content of a web page without permission, often to use that content elsewhere.
Web scraping bots tend to target specific pages or specific elements within these pages. They usually ignore the robots.txt disallow and link nofollow attributes, which can put unnecessary strain on the web servers.
Web crawlers on the other hand respect the rules set by the website and within that scope, explore all crawlable pages.
How Do Web Crawlers Affect SEO?
If a website or page cannot be crawled or specifies that it does not want to be crawled or indexed, then it won’t show up in search results, meaning potential visitors won’t find it. This is why it’s important to make sure that the website settings are configured correctly to allow web crawlers to easily crawl and index the pages you want them to discover.
How Do I Optimise My Website For Easier Crawling?
There are several actions you can take to ensure that your website is optimized for easier crawling:
Use a Sitemap
A sitemap is a file that lists all the pages on your website, making it easier for search engines to find and index your content. Make sure your sitemap is up-to-date and includes all the pages on your website. Most CMS platforms automatically create an XML sitemap that gets updated every time a page is added, deleted, or modified.
For example, you'll see the XML page sitemap looks like this, and it maintained automatically by the YOAST WordPress plugin:
Improve Website Speed
Some website crawlers have a maximum cutoff for page loading time, so it’s important to make sure all of your pages load quickly to ensure web crawlers don’t skip any pages that load too slowly.
Use Internal Linking
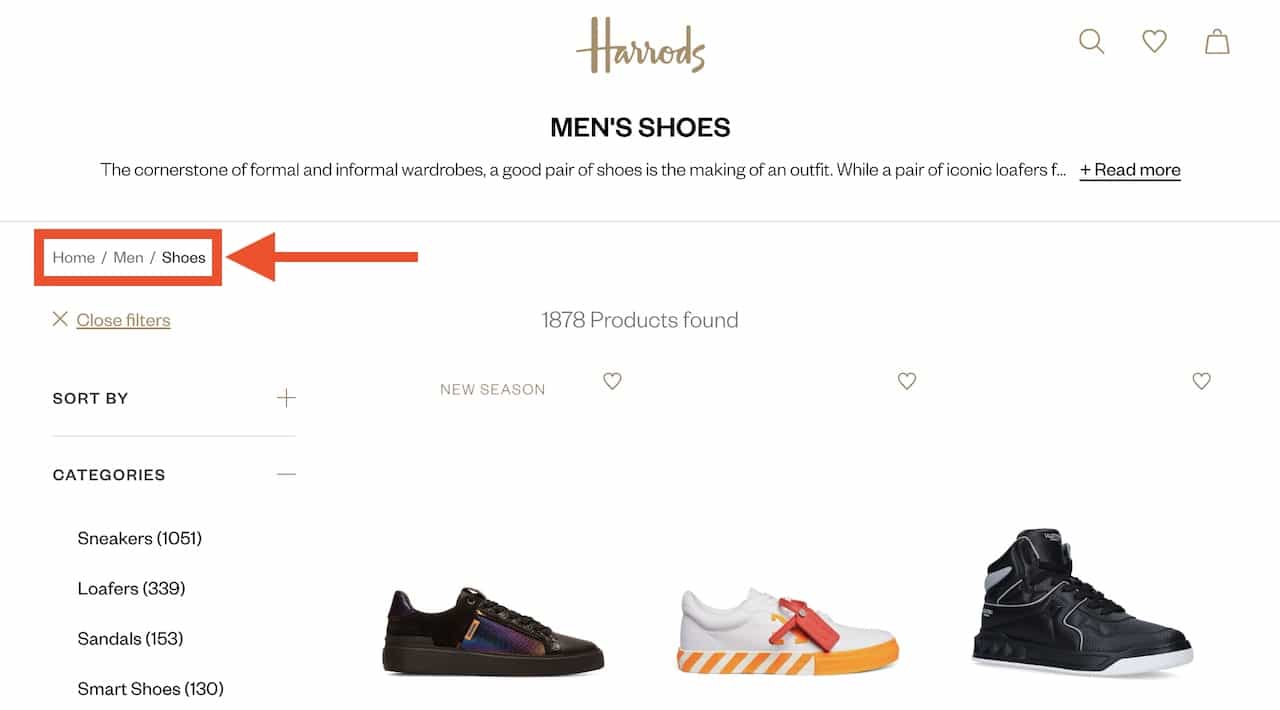
It’s also very important to make sure that pages within your website link to each other, in a logical fashion, and that no page should be orphaned (no links to it). One way to help with this process, especially for larger websites or ones with a deeper hierarchy structure is to implement breadcrumbs. Breadcrumbs are navigational links at the top of a page that help both users and web crawlers to navigate up or down the page hierarchy.
Below is an example of breadcrumbs on the Harrods.com Men's Shoes category:
For a general rule of thumb, on every page, aim to include with the page content at least 2-3 links pointing to other relevant pages on the website.
Configure Robots.txt
Finally, ensure that your robots.txt file has been configured correctly and is not blocking any unintended pages or directories from being crawled or indexed.
Your New Best Friend Does SEO
That’s where Hike comes in. Hike is powered by Kit, your new best friend in the world of SEO. Kit isn’t just a clever piece of tech, it’s a fully-fledged AI agent that works behind the scenes to grow your website traffic.
From building out your keyword strategy to writing SEO-optimised blog posts and fixing technical issues, Kit handles it all. You don’t need to become an SEO guru overnight. You just need Kit.
We understand small businesses, and those that serve them. We know you need traffic and customers, and we know you don’t have big-business budgets. That’s why we built Hike and Kit. Get started today, risk-free.



.webp)