Duplicate content happens when content on or across websites is the exact same, or highly similar, caused unintentionally by the content creator/publisher or because of technical reasons. Google and other search engines do not like duplicate content for many reasons, primarily because it detracts from a high-quality user experience, so it’s important to make sure to avoid it occurring. This article details how duplicate content can occur, and how to fix it if it is found.
Why Is Duplicate Content Important To Avoid?
Search Engines Get Confused
When search engines find multiple versions or variations of the same content, what happens is they don’t know which page or version to index, so there is a high chance that they could end up indexing none.
Another issue is that because multiple pages exist, and each might attract its own unique backlinks, the link equity, authority, and trust are spread out, and the search engines are still confused as to which page is the authoritative one to return.
Ultimately, if two or more variations exist, search engines don’t know which page to rank in their search engine results pages, so the pages may end up competing for rankings, or drop out of the results altogether.
It Burns Crawl Budget
Although most search engines tend to crawl all pages they are able to on a website, having duplicate content causes extra unnecessary crawling to happen, making it less efficient overall and may reduce the frequency of how often each page gets recrawled, because there are more URLs to crawl overall.
Dilutes Page Authority
If there is more than one version of a page, then any backlinks or internal links would fall between these duplicates, which means the page authority that the pages receive would be spread between multiple pages instead of a single page. The total page authority from those backlinks could have massively benefitted a single page in terms of rankings, but instead, it got diluted by having them distributed across duplicate pages.
Get Outranked by Scraped Version
Sometimes page content gets scraped and copied by other websites without permission, and if proper settings aren’t in place, the other website’s version of your content could end up outranking yours. This can obviously hurt your visibility and traffic because Google doesn’t know which version is the original unless it’s specified.
Two Duplicate Content Types
There are two types of duplicate content that are the most common: True duplicates and near duplicates.
True Duplicates
True duplicates are content pieces that are 100% identical, copied word-for-word. This can happen in many scenarios within a website, or via cross-domain duplication caused by incorrect syndication or illegal scraping.
Near Duplicates
Near duplicates are content pieces that are highly similar but only differ by small, minor changes. For example, consider a product page with three color variations, and the product description remains unchanged except for swapping the color or varying features within the text.
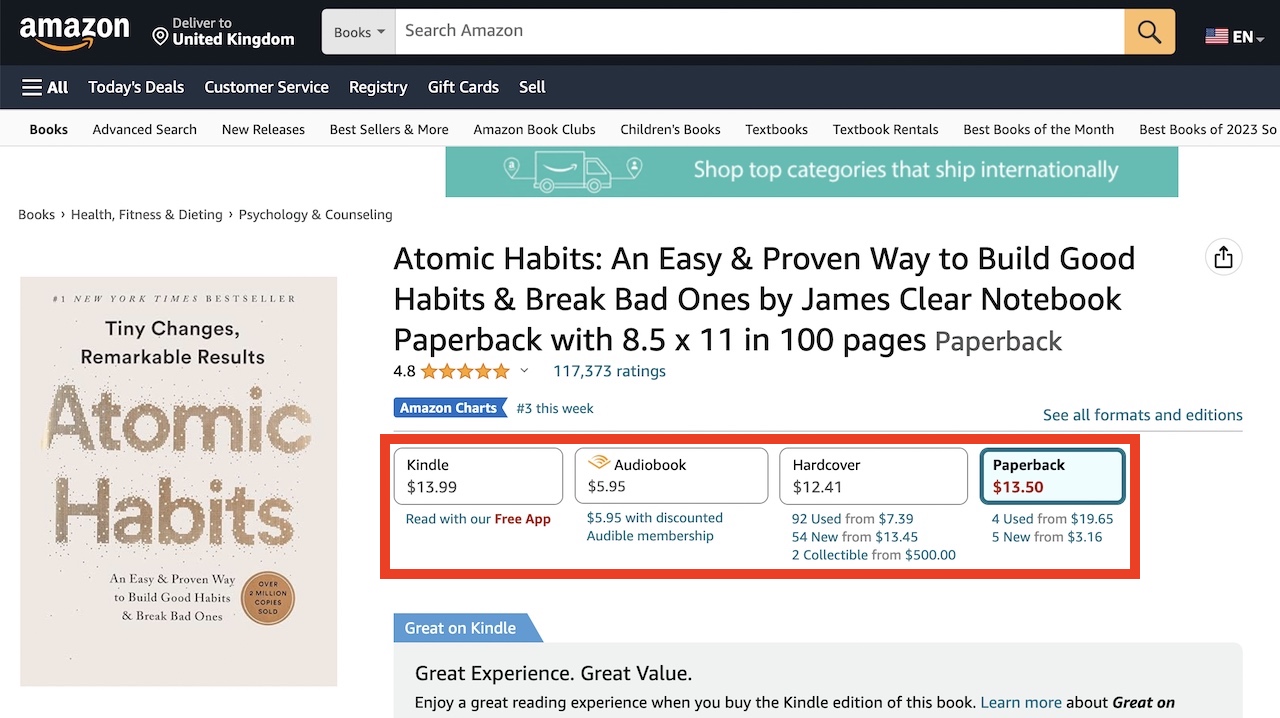
For example, on Amazon's book pages, each book may have multiple formats, and each of those formats have a unique URL with highly similar or exactly the same content. Therefore, in cases like these, it would be beneficial to canonical to a single book page so search engines know which one to rank.
Why Duplicate Content Happens
There are many reasons why duplicate content could happen automatically, even if the content creator had no intention of doing so in the first place. Below are several ways how duplicate content can occur on a website.
Content Publisher Ignorance
Because of a lack of awareness among content publishers of the possible dangers of duplicate content, they may not realize that posting the same content in multiple sections or categories on their websites can create duplicate content. For example, their website might have a blog post about "Healthy Eating" and inadvertently place it in both the "Nutrition" and "Health Tips" sections, leading to the same content being accessible through different URLs. This is especially common for very large sites that have hundreds or thousands of published pages, that are hard to keep track of.
Scraped/Cloned Content
Sometimes, malicious websites copy content from other sources, often without permission. The scraper site might duplicate all of a website’s content, including text, images, and videos, and publish it on its own domain. This not only harms the original content creator but also leads to duplicate content issues, as search engines detect identical content on two different websites.
Duplicate Page Paths
Duplicate page paths occur when the same content is accessible through multiple URLs with slight variations. For instance, "example.com/path-a/page-1/" and "example.com/page-1/" may both lead to the same content, but search engines can interpret them as separate pages.
Trailing Slashes
This issue results from inconsistent URL formatting. Some web servers may treat "example.com/page-1" and "example.com/page-1/" as separate URLs, even though they serve the same content. In such cases, search engines may index both versions, causing potential ranking conflicts. Although less common, sometimes pages with double slashes occur by accident (“example.com/category//page-2”) and load the same content as the page with a single slash.
URL Tracking Parameters
Marketing and tracking parameters, such as "?utm_source=google" in URLs, are used to monitor the source of traffic. However, these parameters can potentially create duplicate content problems. This is also common in instances where tracking is used for affiliate links or session IDs (when logged in). For example, "example.com/page-1" and "example.com/page-1?utm_source=google" may display identical content but could be treated as separate pages by search engines if not dealt with correctly, potentially dividing the ranking authority.
Functional Parameters
E-commerce websites often encounter this issue. Product listings can be sorted or filtered by various criteria like price, popularity, or brand. Each combination of parameters generates a unique URL, even if the products displayed are the same.
For example, "example.com/products?sort=price" and "example.com/products?sort=popularity" might feature the same products but appear as distinct pages to search engines.
Internal search functionality also creates a similar phenomenon, whereby certain searches will produce the same results, which essentially is duplicate content.
For example, “example.com/search?query=health” and “example.com/search?query=healthy” might show the exact same results, but they are two different URLs.
Finally, if using multiple parameters to filter or sort results, swapping the parameters would lead to the same results, but they would be considered separate pages.
For example, “example.com/products/shirts?color=red&size=large” and “example.com/products/shirts?size=large&color=red” would show the same products but the URLs are unique.
HTTP vs. HTTPS
Using the latest HTTPS (SSL) protocol is essential for security as well as SEO, however, sometimes if the server and/or CMS haven’t been configured correctly, both versions of the pages load. Having both versions accessible can lead to duplicate content problems because search engines might perceive "http://example.com/page-1" and "https://example.com/page-1" as separate pages.
WWW vs. Non-WWW
Some websites can still be accessed with or without "www" in the URL. If the preferred version isn't specified, search engines may treat "www.example.com/page-1" and "example.com/page-1" as distinct URLs, potentially resulting in duplicate content issues. It’s always goo practice to choose one version of the domain and redirect the other version. Choosing your URLs to be with www or without www is a preference, so either works.
Staging Servers
Web developers use staging servers to test and develop website updates. If these servers are unintentionally accessible to search engines, it can lead to duplicate content. For example, “staging.example.com/page-1” may get indexed alongside the live version on “example.com/page-1”.
Homepage Duplicates
Homepages can have multiple URL variations, such as "example.com" "example.com/index.html" or “example.com/home”. Despite all leading to the same homepage, they can be interpreted as separate pages by search engines, leading to potential ranking issues. This is less common today as most CMS platforms will automatically redirect the other versions.
Case-Sensitive URLs
Some web servers treat uppercase and lowercase letters differently in URLs. For instance, "example.com/Page-1" and "example.com/page-1" may be considered as distinct pages. This can create confusion for search engines and users. Having a server-level redirect rule if possible will force rewriting of the URLs into lowercase, avoiding this issue altogether.
Printer-Friendly URLs
Many websites offer printer-friendly versions of their pages, which may append "/print" or similar modifiers to the URL. These versions can result in duplicate content problems, with "example.com/page-1" and "example.com/page-1/print" being seen as separate pages even though they serve the same content.
Mobile-Friendly URLs
To optimize the user experience on mobile devices, websites often create separate mobile versions. For example, "example.com/page-1" and "m.example.com/page-1" might offer the same content but are treated as distinct URLs by search engines, potentially causing duplicate content issues.
International Pages
Websites with international content targeting different regions may have separate URLs for each variation. For instance, "example.com/us/page-1" and "example.com/uk/page-1" may contain the same or very similar content but are considered separate pages to cater to international audiences. This is why in these cases, hreflang tags are used to let search engines know for which region each content piece is for.
AMP URLs
Accelerated Mobile Pages (AMP) are designed to load quickly on mobile devices. Some websites may have separate AMP URLs, like "example.com/page-1" and "example.com/amp/page-1" for the same content, potentially creating duplicate content issues.
Tag and Category Pages
Content management systems often generate tag and category pages that include excerpts or links to related posts. These tag and category pages can generate multiple URLs with similar content, like "example.com/tag/tech" and "example.com/category/technology", especially if the content was categorized and/or tagged across multiple tags and categories.
Paginated Comments
On content-heavy pages with paginated comments, each comment page generates a new URL. For example, "example.com/article-1?page=1" and "example.com/article-1?page=2" may serve similar content, but they are seen as separate pages by search engines due to the differing query parameters.
Product Variations
E-commerce websites frequently offer product variations like color, size, or style. Each combination generally has a unique URL, even if the core product description remains the same. For instance, "example.com/product-red-variation" and "example.com/product-blue-variation" or "example.com/product?color=red" and "example.com/product?color=blue" may be treated as distinct pages by search engines, despite the shared content.
Methods to Prevent Duplicate Content
Now that you know of different ways how duplicate content can happen, it’s important to know what to do about it practically, so the potential issues can be eliminated.
Consolidate Pages
Consolidating pages involves identifying and merging similar or duplicate content into a single, comprehensive page. This is typically done by setting up 301 redirects from the old URLs to the consolidated one. The main objective is to reduce redundancy and create a clear, authoritative source of information. By doing so, you ensure that search engines index and rank the preferred version, streamlining your website's content structure and enhancing user experience. Consolidation is especially valuable when dealing with multiple versions of the same content scattered across different URLs.
Canonical Tags
Canonical tags, implemented as <link rel="canonical"> within a page's HTML, serve as a directive to search engines, indicating the canonical or preferred URL for that specific content. They are a powerful tool in preventing duplicate content issues, particularly when dealing with similar pages that have minor variations, such as trailing slashes or parameter-based URLs. By specifying the canonical version, you guide search engines in ranking and indexing the most important page, which helps preserve the SEO value and prevents dilution of search engine authority.
For example, on this page, the canonical tag is self-referencing, meaning it points to itself. This prevents unintentional duplicates arising from technical issues or misconfiguration of the server or CMS.
It’s also important to have self-referential canonical tags on pages that don’t have duplicates to guarantee that only that page will be returned in search results. This is also important to prevent issues if the content is scraped and reposted on third-party sites because self-referential canonicals will ensure your site’s version gets credit as the “original” content piece.
Meta Tagging
The "noindex" meta tag is a powerful method to prevent specific pages from being indexed by search engines. By placing this tag in the HTML header of particular pages, you instruct search engines not to include those pages in their search results. This approach is particularly useful for eliminating the risk of duplicate content problems associated with non-essential pages, such as login pages, thank-you pages, or temporary promotional pages, which should not appear in search engine results.
This method should not be used in place of canonical tags, as it is purely to hide pages that should not be indexed in the first place.
Redirects
Redirects, specifically 301 (permanent) redirects, are an effective solution for resolving duplicate content issues when URLs change or when you want to consolidate multiple pages into one authoritative version. When users and search engines access an old URL, they are automatically redirected to the new, preferred URL. This ensures that traffic and SEO value are transferred, while duplicate versions are phased out.
Parameter Handling
Managing URL parameters effectively is crucial for websites with dynamic content, such as e-commerce sites with sorting and filtering options. Proper configuration within your CMS, in conjunction with methods like the rel="canonical" tag, allows you to specify how parameters should be treated by search engines. This prevents search engines from indexing numerous versions of the same content with different parameters and guides them toward the main content.
Pagination Handling
Websites with paginated content, such as articles with multiple pages, can benefit from the implementation of rel="prev" and rel="next" HTML tags. These tags establish the relationship between paginated pages, helping search engines understand the structure. Additionally, offering a "View All" option for content that can fit on a single page can reduce pagination-based duplicate content issues. This approach enhances user experience while providing clarity to search engines.
Robots.txt
The robots.txt file is a valuable tool for excluding specific sections or pages of your website from search engine crawlers. By disallowing the crawling and indexing of non-essential or duplicate content, such as archive pages, login pages, or internal search results, you can effectively prevent these pages from causing duplicate content issues in search engine results. Keep in mind, even though it’s a quick and simple fix, disallowing pages or sections of a website doesn’t guarantee that it won’t be indexed. If you want to be sure pages don’t get indexed, include a robots noindex meta tag.
Internal Linking
Proper internal linking practices involve strategically placing links between related pages on your website. This not only improves user navigation but also guides search engines to the preferred version of a page. By using descriptive anchor text, you can indicate the significance of a linked page, reinforcing its authority and reducing the likelihood of competing duplicate versions within your site. Internal linking doesn’t replace the other methods of dealing with duplicate content, such as canonicals, but it supports them to make it clearer to search engines which content pieces are the primary ones.
Hreflang for International
For websites with international versions targeting different languages and regions, implementing hreflang tags is essential. Hreflang tags specify the language and regional targeting of each page, ensuring that search engines and users are directed to the correct localized content. This not only eliminates confusion but also prevents duplicate content issues across international versions, enhancing the global visibility and relevance of your website.
Use Tools
Use Google Search Console to easily spot duplicate content on your website as well as quickly allow you to set the preferred domain of your site, whether it’s the www or non-www version.
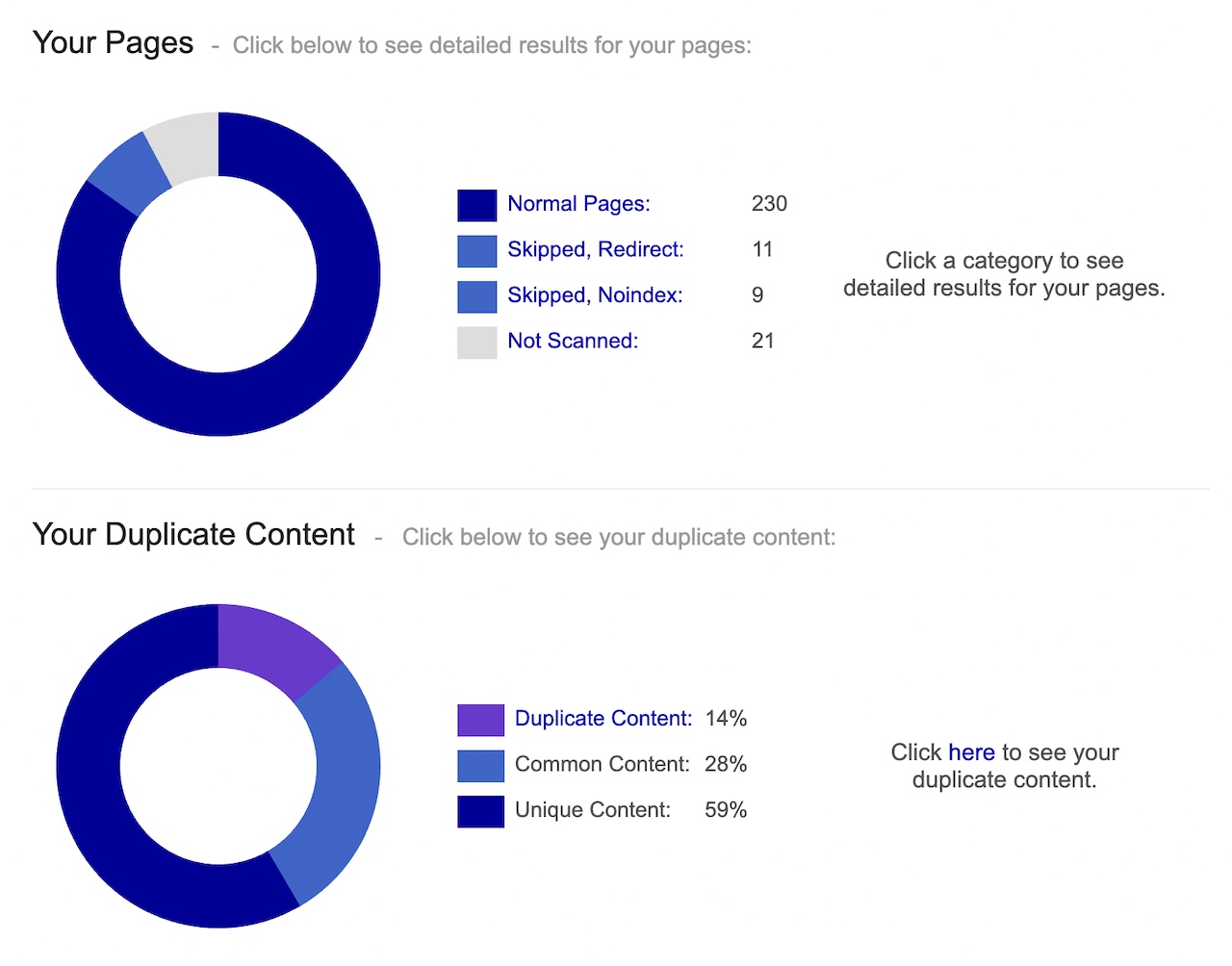
Another popular tool many use is Siteliner.com to scan a website and flag content that is highly similar.
For example, below you can see that Siteliner discovered approximately 14% of scanned pages of a website as potential duplicate content:
You can also use Hike SEO to automatically flag duplicate content so you can review and fix it right away. The duplicate content will be flagged up for review in the "Actions" section of the platform.
What if My Content Has Been Copied by Others?
If your content has been copied without your permission, there are a few things you can do to prevent it from negatively affecting your original content.
Firstly, contact the webmaster responsible for the site and ask them to remove the content if you own the copyrights. Explain to them that it was used without permission and that you would like it taken down immediately.
If a polite message doesn’t prompt any responses from the website owner, sending a DMCA notice is a more forceful approach that should get results.
Secondly, make sure that your website has self-referencing canonical tags so that Google knows that your content is the original version.
Kit Does What Agencies Charge a Fortune For
That’s where Hike comes in. Hike is powered by Kit, the AI assistant that brings expert-level SEO to your fingertips, without the scary price tag. Kit takes care of all the bits you don’t have time for: content, keywords, fixes, local SEO, and more.
And here’s the kicker: Kit doesn’t just tell you what to do, it actually does it. It’s like hiring an agency that works 24/7, never ghosts you, and doesn’t charge $1,000+ a month.
We understand small businesses, and those that serve them. We know you need traffic and customers, and we know you don’t have big-business budgets. That’s why we built Hike and Kit. Get started today, risk-free.


.webp)