Get more customers, without more effort.
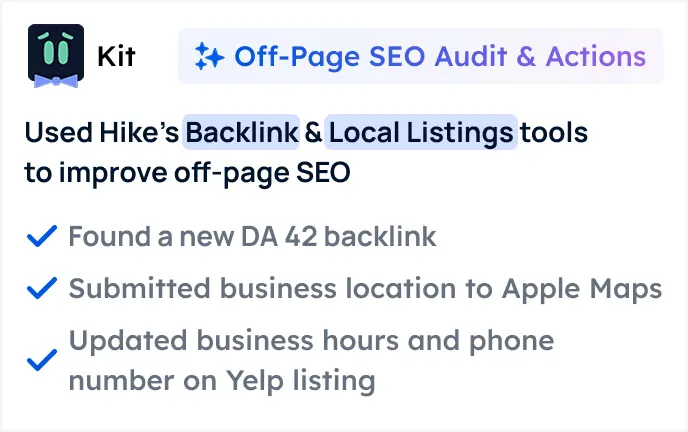
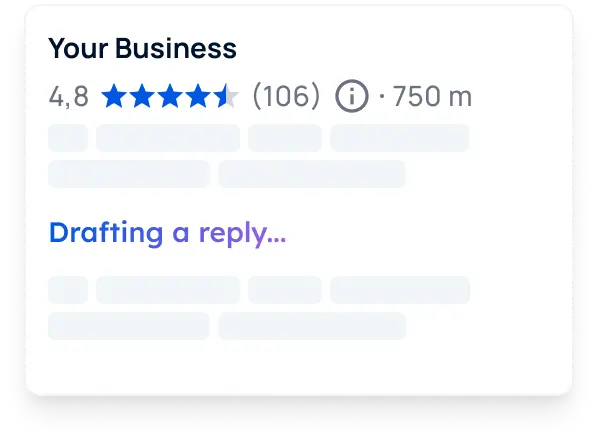
Hike has helped 10,000+ small companies grow online since 2017. Now powered by Kit, our AI SEO expert that gets you found on Google, ChatGPT, and LLMs - increasing your visibility and growing your business, at a price you can afford.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Love it or get a full refund
No long term commitments
14-day money back guarantee









.webp)























.webp)